
Fun times optimizing 6502 assembly!
Each month Shallan’s Discord has a coding challenge and every second month it is an optimization challenge, Let’s look back at the previous challenge!

January Coding Challenge
A couple of months ago I participated in a Commodore 64 size coding challenge, the idea was to reproduce this screen by loading and auto starting code in VICE 3.4 to keep the challenge consistent.

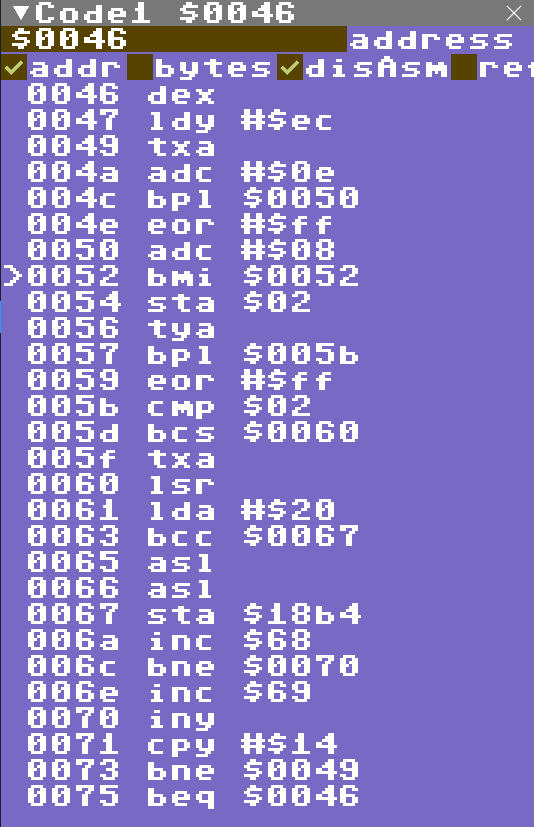
So that was a lot of fun and I ended up winning by patching CHROUT in zero page and some clever drawing logic! Here is the code I made, the entry address is $73, Z is set and x and y are convenient values, this is the self modified code after the screen has drawn with the N flag set from the adc on the line above (PC = $52):
For more details about that challenge check out this gist: Spiral challenge
But this post is about the March challenge, the plan was to just list the iterations in chronological order but that came out looking a little bit insane, basically trying combinations of a few tricks over and over with different results. Instead I’ve categorized the process in a more intuitive structure but it is still an very long post for just 141 bytes of code and tables. Let’s move on.
The New Challenge
For March, Shallan came up with a much more ambiguous challenge combining both size and speed coding by going for the lowest product of size AND cycles to execute. So a small challenge program generates a pattern in the upper left quadrant of the screen and the code should produce a kaleidoscope image by mirroring the pattern horizontally and vertically. This also includes mirroring the symbol screen codes which are defined at font position without any reasoning.

The challenge program calls the code and displays the number of cycles used by the code at the bottom of the screen. The cycle counter uses the timer interrupts and displays an accurate result so you can review your code prior to submitting it to the competition.
If you’re interested in these challenges you can find the discord link and more on Shallan’s twitch page: https://www.twitch.tv/shallan50k/
Rules
MARCH KALEIDOSCOPE CHALLENGE
1. The aim is to write an efficient function to correctly mirror the pattern generated by the main program. The pattern is made up of 24 different PETSCII symbols.
2. The pattern must be mirrored both horizontally and vertically so as to fill a 40×24 section of the screen. The last line is used for outputting cycle timing results.
3. The main program will generate a random pattern in the top left quadrant of the screen, start a timer and then run the submitted code. When the code returns with an RTS the timer is stopped and the cycle count displayed.
4. No verification routine is available to submissions, entries must be self validated.
5. On stream on the day of competition closure, each submission will be loaded into a verification version of the main program. If the output passes it will receive a score, calculated from the average cycle count of 3 consecutive runs multiplied by the number of bytes used between $c000 and $cfff. Lowest score wins.
6. Submissions must be made in the form of a prg containing just the code and data for $c000-$cfff, the main program should NOT be included.
7. Closing date for entries is 9:30pm GMT on the 27th March 2021.
8. All code, vars and tables must reside between $c000-$cfff. The entry point will be $c000.
9. Screen ram will remain at the default of $0400 and must not be changed.
10. All zeropage is free for use as BASIC and Kernal are banked out.
11. The main program disables the screen so that bad lines are not present for the most accurate cycle timing. During testing you can disable this if needed.
12. The main program uses two CIA timers to accurately time the function, do NOT disable stop or otherwise change these timers or the submission will not count.
13. The function must be able to be called multiple times so any self modifiedc code must set itself up.
Additional clarifications:
Going to add this additional point: All main code in MarchCompo.asm will remain exactly as it is in the final verification wrapper, with the exception of the JSR $c000 call which will be replaced by a jump to the appended verification code. So feel free to utilise any values of use there. However note that the verification routine will also perform a checksum of this area too so no sneaky trying to change things.
While zero page use is ok for variables zero page should not be used for code (this was a discussion in the middle of development, at this point I had already achieved better performance by not running any code in zero page anyway).
Algorithm
To summarize the algorithm I’m going forward with, the code will loop each row in the top left quadrant from top to row 12, and within that loop from left to screen center read one character, mirror it horizontally using a look-up table, and put it on a mirrored horizontal position on the same row.

Next take the horizontally mirrored character, mirror it vertically and put it on a position mirrored both horizontally and vertically. Next mirror that character vertically and put it on a mirrored vertical position from the original character.

Repeat this for the 240 character positions. As I go I’m finding improvements to this algorithm that I will make a note of.
A note about my code syntax
I’m including some code snippets throughout this post and I’m just going to use the syntax from my assembler. The biggest difference from other assemblers seems to be that I use braces ( { and } ) to note scopes similar to C, and I’ve added ! as a shortcut to the previous opening brace ( { } and % as a shortcut to the next closing brace ( } ). I’ll post the final code at the end without any unique syntax if you find it hard to read the code in the post.

Here is a small example to show how it is used:
; returns the length of a zero terminated string
; that the zero page pair zpString points to in
; memory.
; returns y = length, or $80 if the string is bad.
Strlen:
{
ldy #0
{
lda (zpString),y
beq % ; found a 0, exit
iny
bpl ! ; as long as not $80 chars repeat the loop
}
rts
}Coding challenges on Discord
There are other C64 coding challenges but they tend to be along the lines of here’s the challenge and here’s the deadline. Once you’re done you post the result and that’s it.
What makes these challenges a bit different is that we talk about them while we’re working on them carefully trying to not spoil our secrets but still boast about the progress we’re making.

In the beginning there is a lot of sharing of scores and screenshots which gets replaced by announcements of savings but no totals followed by more and more cryptic updates.
This gives the challenge additional fuel and lots of second hand guessing what the rest of the competitors are up to.

There is a prize for the winner and runner up but you can’t get the prize if you already won it. This leads up to the presentation at the end of the month which so far has been around midnight between the last Saturday and Sunday of the month.
Competition results
Here are the official scores from the challenge, as you can see I was not first which means I win more knowledge!

I’ll compare Zzsila’s code with mine towards the end. First let’s go through what considerations went in to my own process.
Congrats to all participants who completed the challenge! I hope everyone picks up some new skills from their own process and other participants!
Speed code is always the fastest code *
So just to get started the fastest solution would just be speed code right? I hadn’t realized the size mattered yet so here is my first attempt, this fills the entire allowed memory space of $c000 – $cfff (4096 bytes). Note that “rept” is a keyword that repeats the code within the following braces, and within those braces rept is also a symbol with the repeat count.
const horiz = 2;-$20
const vert = horiz + $7d
org $c000
ldx #$20
{
txa
sta.z horiz,x
sta.z vert,x
inx
cpx #$7d+1
bcc !
}
; half corner (a = $7d)
sta.z horiz+$6d
sta.z vert+$6e
; curves
lda #$55
sta.z horiz+$49
sta.z vert+$4a
ldx #$49
stx.z horiz+$55
stx.z vert+$4b
inx
stx.z horiz+$4b
stx.z vert+$55
inx
stx.z horiz+$4a
stx.z vert+$49
; full corners, x = $4b
inx
stx.z horiz+$7a ; $4c
stx.z vert+$4f
; diagonals
inx
stx.z horiz+$4e ; $4d
stx.z vert+$4e
inx
stx.z horiz+$4d ; $4e
stx.z vert+$4d
inx
stx.z horiz+$50 ; $4f
stx.z vert+$4c
inx
stx.z horiz+$4f ; $50
stx.z vert+$7a
lda #$7a
sta.z horiz+$4c
sta.z vert+$50
; half corners
ldx #$6d
stx.z horiz+$7d
stx.z vert+$70
inx
stx.z horiz+$70
stx.z vert+$7d
; t-junctions
lda #$6b
sta.z horiz+$73
ldx #$73
stx.z horiz+$6b
dex
stx.z vert+$71
dex
stx.z vert+$72
dex
stx.z horiz+$6e
stx.z vert+$6d
{
rept 10 {
row = rept
rept 20 {
col = rept
ldx $400 + row * 40 + col
ldy.z horiz,x
sty $427 + row * 40 - col
ldx.z vert,y
stx $7bf - row * 40 - col
ldy.z horiz,x
sty $798 - row * 40 + col
}
}
}
lda #0
sta $ff
ldy #19
{
ldx $400+10*40,y
sty $fe
lda.z horiz,x
ldy $ff
sta $400+10*40+20,y
tax
lda.z vert,x
sta $400+13*40+20,y
tax
lda.z horiz,x
ldy $fe
sta $400+13*40,y
ldx $400+11*40,y
lda.z horiz,x
ldy $ff
sta $400+11*40+20,y
tax
lda.z vert,x
sta $400+12*40+20,y
iny
sty $ff
tax
lda.z horiz,x
ldy $fe
sta $400+12*40,y
dey
bpl !
}
rts
So turns out the result here is pretty disappointing, around 9316 cycles, multiplied with the size (4096) the result is above 38 megacyclebytes or MCB, a term we came up with to discuss the challenge in the discord group.

The mirroring lookup table
As you can see in the example above I’ve just hand coded the lookup table for mirroring horizontally and vertically. This is probably the least intuitive way to do it but here’s the idea:
The used characters are $20 – $7d so slightly less than 96 which means there is enough room on zero page for two tables, one for mirroring horizontally and one for mirroring vertically.
Most characters are not mirrored so the values for both the horizontal and vertical table are the same as their indices. Then just add the exceptions which are the petscii screen codes used:
- $49,$55,$4b,$4a ;Curves
- $50,$4f,$7a,$4c ;Full corners
- $6e,$70,$7d,$6d ;Half corners
- $73,$6b,$71,$72 ;T junctions
- $40,$42 ;Middle lines
- $5b,$56 ;Crosses
- $4e,$4d ;Diagonals
- $51,$5a ;Filled Circle + Diamond
Better than speed code
My next attempt was nearly the same code as the unrolled loop, but replaced with a loop. This became 246 bytes but isn’t quite correct as it is missing the last line.
// setup code from above is the same
lda #11
sta $fd
{
lda #0
sta $ff
ldy #19
{
src = *+1
ldx $400,y
sty $fe
lda.z horiz,x
ldy $ff
dst1 = *+1
sta $400+20,y
tax
lda.z vert,x
dst2 = *+1
sta $400+23*40+20,y
tax
lda.z horiz,x
iny
sty $ff
ldy $fe
dst3 = *+1
sta $400+23*40,y
dey
bpl !
}
clc
lda src
adc #40
sta src
{
bcc %
inc src+1
inc dst1+1
clc
}
adc #20
sta dst1
{
bcc %
inc dst1+1
}
sec
lda dst2
sbc #40
sta dst2
{
bcs %
dec dst2+1
dec dst3+1
sec
}
sbc #20
sta dst3
{
bcs %
dec dst3+1
}
dec $fd
bne !
}
So not correct and still 13862 cycles, but still an improvement by over 10 times! Now the score is around 3.4 MCB!

More effective mirroring tables
So hard-coding each character mirror index is not that great, but also aside from space only the screen codes in the generator can appear on-screen, so only those indices in the lookup tables need to be filled out.
So here is the implementation with an index table and the values to insert for those indices for the horizontal and the vertical mirroring tables.
zp_trans_size = 24
horiz = $00
vert = $40
ldy #zp_trans_size-1
{
ldx orig_chars,y ; 16
lda horiz_mirror_chars,y
sta.z horiz,x
lda vert_mirror_chars,y
sta.z vert,x
dey
bpl !
}
orig_chars:
dc.b $55,$49,$4a,$4b //Curves
dc.b $4f,$50,$4c,$7a //Full corners
dc.b $70,$6e,$6d,$7d //Half corners
dc.b $6b,$73,$71,$72 //T junctions
dc.b $40,$42 //Middle lines
dc.b $5b,$56 //Crosses
dc.b $4d,$4e //Diagonals
dc.b $51,$5a //Filled Circle + Diamond
horiz_mirror_chars:
dc.b $49,$55,$4b,$4a ;Curves
dc.b $50,$4f,$7a,$4c ;Full corners
dc.b $6e,$70,$7d,$6d ;Half corners
dc.b $73,$6b,$71,$72 ;T junctions
dc.b $40,$42 ;Middle lines
dc.b $5b,$56 ;Crosses
dc.b $4e,$4d ;Diagonals
dc.b $51,$5a ;Filled Circle + Diamond
vert_mirror_chars:
dc.b $4a,$4b,$55,$49 ;Curves
dc.b $4c,$7a,$4f,$50 ;Full corners
dc.b $6d,$7d,$70,$6e ;Half corners
dc.b $6b,$73,$72,$71 ;T junctions
dc.b $40,$42 ;Middle lines
dc.b $5b,$56 ;Crosses
dc.b $4e,$4d ;Diagonals
dc.b $51,$5a ;Filled Circle + DiamondFinding some bytes
The mirroring tables are built with an original table to find the index and two tables of mirrored values to insert.
The challenge base program conveniently contains the original petscii screen codes at address $0a13 so the first table is just a reference to that address saving some precious 24 bytes!

Skipping Spaces & using Zero Page
Since you don’t need to process spaces a loop checking for spaces will usually produce a better result than processing every character. On average it seems about 1/3 of the characters will be non-space.
In addition the Zero Page is also allowed so to make the most of the loop logic was moved to zero page and the setup left in the $c000 area. I later found out this was against the rules but it was a step forward.

Here is the zero page section of the third attempt. There is a check that the character is a valid symbol before attempting to mirror it. To mirror the column offset it uses XOR with $1f and adding 8 so that column 0 is mirrored at 39, and column 19 is mirrored at 20. The row counter is copied as a zero page byte along with the zero page code block!
const horiz = 2-$40
const vert = horiz+$7e-$40
const zp_code = vert + $7e
eval horiz
eval vert
org zp_code
zp_start
zp_rows
dc.b 12 ; loop count for rows
zp_loop
{
src = *+1
ldx $400+11*40,y
cpx #$40
bcc no_char
tya
eor #$1f
tay
lda.z horiz,x
dst1 = *+1
sta $400+11*40+39-$1f,y
tax
lda.z vert,x
dst2 = *+1
sta $400+12*40+39-$1f,y
tax
tya
eor #$1f
tay
lda.z horiz,x
dst3 = *+1
sta $400+12*40,y
no_char
dey
bpl !
}
rts
zp_size = * - zp_start
And the main program. This version unfortunately includes several iterations including making a lookup table for mirroring petscii screencodes horizontally and vertically in zero page by setting the horizontally and vertically mirrored petscii indices at offsets.

Another iteration was realizing that the challenge program contains a list of the possible characters already and the rules allow using the challenge program data so that saved 24 bytes! (the number of allowed characters except space)
incsym "kalei3zp.sym"
zp_trans_orig = $a13
zp_trans_size = 24
org $c000
rept 12 {
eval $400+40*(11-rept)
eval $400+40*(11-rept)+(39-$1f)
}
rept 12 {
eval $400+40*(12+rept)
eval $400+40*(12+rept)+(39-$1f)
}
ldy #zp_trans_size-1
{
ldx zp_trans_orig,y ; 16
lda zp_trans_horiz,y
sta.z horiz,x
lda zp_trans_vert,y
sta.z vert,x
dey
bpl !
}
ldx #zp_size-1
{
lda zp_code_read,x
sta zp_start,x
dex
bpl !
}
{
ldy #20
jsr zp_loop
sec
lda.z src
sbc #40
sta.z src
{
bcs %
dec.z src+1
dec.z dst1+1
sec
}
adc #8-1
sta.z dst1 ; C always clear here
lda.z dst3
adc #40
sta.z dst3
{
bcc %
inc.z dst3+1
clc
}
lda.z dst2
adc #40
sta.z dst2
{
bcc %
inc.z dst2+1
}
dec.z zp_rows
bne !
}
rts
zp_code_read:
incbin "kalei3zp.bin"
zp_trans_horiz:
dc.b $49,$55,$4b,$4a ;Curves
dc.b $50,$4f,$7a,$4c ;Full corners
dc.b $6e,$70,$7d,$6d ;Half corners
dc.b $73,$6b,$71,$72 ;T junctions
dc.b $40,$42 ;Middle lines
dc.b $5b,$56 ;Crosses
dc.b $4e,$4d ;Diagonals
dc.b $51,$5a ;Filled Circle + Diamond
zp_trans_vert:
dc.b $4a,$4b,$55,$49 ;Curves
dc.b $4c,$7a,$4f,$50 ;Full corners
dc.b $6d,$7d,$70,$6e ;Half corners
dc.b $6b,$73,$72,$71 ;T junctions
dc.b $40,$42 ;Middle lines
dc.b $5b,$56 ;Crosses
dc.b $4e,$4d ;Diagonals
dc.b $51,$5a ;Filled Circle + DiamondSo the result? A teeny tiny 162 bytes and pretty good cycle counts from around 8000 to 9500 so at an average 1.4 MCB, an improvement by 2 MCB from the previous incomplete result.

Bad Iterations
Next iteration was not copying the loop code to zero page, just using the zero page for row counter and screen pointers. This iteration did not improve the score but not a large difference!

Here is the changed zero page copy & main loop:
ldx #8
{
lda zp_ptrs,x
sta $f6,x
sta $fb,x
dex
bpl !
}
{
clc
lda.z $fe
adc #40
sta.z $fe
{
bcc %
inc.z $ff
clc
}
lda.z $fc
adc #40
sta.z $fc
{
bcc %
inc.z $fd
}
ldy #20
zp_loop
{
lda ($f7),y
{
cmp #$40
bcc %
tax
tya
eor #$1f
tay
lda.z horiz,x
sta ($f9),y
tax
lda.z vert,x
sta ($fe),y
tax
tya
eor #$1f
tay
lda.z horiz,x
sta ($fc),y
}
dey
bpl !
}
sec
lda.z $f7
sbc #40
sta.z $f7
{
bcs %
dec.z $f8
dec.z $fa
sec
}
adc #8-1
sta.z $f9 ; C always clear here
dec.z $f6
bne !
}
rts
zp_ptrs:
dc.b 12
dc.w $400+11*40
dc.w $400+11*40+39-$1fCompression?
So another idea: compressing the mirroring tables a bit. Unfortunately even if the code is fairly simple it still consumes more bytes than the tables in raw form. Here is the code up to the loop which is the same as the previous attempt:

ldx #8
{
lda zp_ptrs,x
sta $f6,x
sta $fb,x
dex
bpl !
}
ldy #zp_trans_size-1
{
lda zp_trans_orig,y ; 16
tax
sta horiz,x
sta vert,x
cpy #12
dey
bpl !
}
{
sty $f0
lda zp_trans_orig,y ; 16
tax
eor #1
tay
lda zp_trans_orig,y
sta horiz,x
txa
eor #2
tay
lda zp_trans_orig,y
sta vert,x
ldy $f0
dey
bpl !
}
lda #$6b
sta horiz+$73
lda #$73
sta horiz+$6b
ldx #$71
stx.z vert+$72
inx
stx.z vert+$71
ldx #$4d
stx.z horiz+$4e
stx.z vert+$4e
inx
stx.z horiz+$4d
stx.z vert+$4dColumn Flipping Table
So with two attempts making things worse, back to the version with the loop code in zero page! this is just a tiny change where instead of mirroring the column by tya/eor #$1f/tay the code instead uses a 40 byte flipping table where each element contains 40 minus its index:
zp_loop
{ ; space: 14+, char: 53+
src = *+1
ldy $400+11*40,x
cpy #$40
bcc no_char
lda horiz,y
ldy.z flippo,x
dst1 = *+1
sta $400+11*40,y
tax
lda.z vert,x
dst2 = *+1
sta $400+12*40,y
tax
lda.z horiz,x
ldx.z flippo,y
dst3 = *+1
sta $400+12*40,x
no_char
dex
bpl !
}
rtsThis saves 4 cycles for each character that needs mirroring, finally an iteration that is an improvement!
After this many iterations just moves code around, tries to do multiple things in a single loop to save bytes. Nothing particularly useful but finding a little bit of memory or performance here and there kicking the score a little lower.
At this point I’m below 1.25 MCB, this is better than I had expected when I started so definitely happy and I can find more optimizations fairly easily at this stage. But I think it is becoming fairly clear that copying code into zero page is not beating just running the code where it is at. I also learn that it is against the rules to run code in the zero page, not explicitly spelled out in the text rules but it is clarified on Twitch and Discord.
Profiling
Up to this point I’ve been using the base code cycle counter and just running the code about 15 times and taking the average. Not only is that tedious but also not accurate at all when the savings per iteration is just a few cycles or a byte. Unfortunately counting cycles is even more tedious!

This is my lazy solution to accurate cycle counting:
Running the code with all spaces would tell me the exact cost without doing the mirroring, and running the code all mirrored characters and then dividing the difference from the previous test by 240 tells me the cost to mirror each character!
Simply changing the branch in the mirror loop from bpl to bcc shows the cycle count for all spaces, then using bcs instead gives me the cycle count for mirroring all 240 characters.


In the examples above the number of cycles used if no characters are mirrored is 3937 cycles, and the number of cycles used if all characters are mirrored is 14737 cycles. Given that there are 240 character positions that are handled the cost of this code in cycles is 3937 + mirror characters * 45.
Running a number of tests it seems like 84.5 is a good average number of mirrorable characters, so now I have a method for accurately profiling an iteration with just two test runs! The average cost in cycles of the above example is then 7739.5.
Indirect Indexing
It has been handy to deal with indexed absolute addressing (lda $400,x) rather than zero page indirect indexing (lda ($fe),y) because both the x and y register can be used, but one of the costs is that there are four screen row pointers to maintain (one for source, one for destination top right, and another two for destination bottom right and bottom left).

With column index mirroring (mirrored column = 39-original column) only two pointers are needed but only the y register can be used to index the rows.
The cost of copying code to zero page or setting up four pointers is higher than the cost of indirect indexing so now there is no longer any justification to copy code to zero page.
Calculating column mirroring
Setting up a table on zero page for mirroring columns is intuitive but there is a cost in setting that up too, and you need to load the value into the accumulator and then transfer back to y. Additionally a byte is lost because there is no zero page y indexed lda!

So instead the mirroring can be done by calculating y = 39-y, or tya / eor #$ff / adc #40 / tay. Rather than doing it twice just storing the current column on the zero page and loading back saves two bytes.
Here’s what the inner loop looks like with this adjustment:
ldy #19
{
lda ($f7),y
{
cmp #$40
bcc %
tax
tya ; C set from bcc
sta $f5
eor #$ff
adc #39
tay
lda.z horiz,x
sta ($f7),y
tax
lda.z vert,x
sta ($f9),y
tax
lda.z horiz,x
ldy $f5
sta ($f9),y
}
dey
bpl !
}Order of rows
So I’ve been processing the rows for original characters from top to bottom with this flow:
- Set a loop counter (zero page) to 12 and screen pointers (top row and bottom row)
- update a row, starting with the top
- increment the top row pointer and decrement the bottom row pointer
- decrement the loop counter and repeat until 0

Here is a version of this
ldx #5-1
{
lda zp_ptrs,x
sta $f6,x
dex
bpl !
}
{
ldy #19
{
...
}
clc
lda $f7
adc #40
sta $f7
{
bcc %
inc $f8
}
sec
lda $f9
sbc #40
sta $f9
{
bcs %
dec $fa
}
dec $f6
bne !
}
rts
zp_ptrs:
dc.b 12 ; loop counter $f6
dc.w $400 ; top row ($f7)
dc.w $400+23*40 ; bottom row ($f9)
What opportunities are there for starting in the middle?
So starting in the middle, the top row gets subtracted by 40 bytes each row and the bottom row added 40 bytes. By moving the bottom row addition before the column loop both zero page row pointers can start at the same value!
lda #12
sta $f6
lda #<$400+11*40
sta $f7
sta $f9
lda #>$400+11*40
sta $f8
sta $fa
{
{
clc
lda $f9
adc #40
sta $f9
{
bcc %
inc $fa
}
}
ldy #19
{
...
}
sec
lda $f7
sbc #40
sta $f7
{
bcs %
dec $f8
}
dec.z $f6
bne !
}
rtsSo the branches can be rearranged a little so that the row counter becomes a page counter instead! Also the first clc can be replaced with sec that is only needed the first time through the loop and when pages are stepped!
lda #2 ; 2 pages instad of 12 rows ($500 -> $400 -> $300)
sta $f6
lda #<$400+11*40
sta $f7
sta $f9
lda #>$400+11*40
sta $f8
sta $fa
{
sec
{
{
lda $f9
adc #40-1
sta $f9
{
bcc %
inc $fa
}
}
ldy #19
{
...
}
sec
lda $f7
sbc #40
sta $f7
bcs !
}
dec $f8
dec $f6
bne !
}
rtsThis have reduced the number of instructions quite a bit already! There are more opportunities here but let’s move on!
Saving a byte using the stack
Is it worth sacrificing a handful of cycles to save a byte? There are around 8000 cycles and only around 140 bytes so one byte should be worth nearly 60 cycles?
So the idea here is that in the character mirroring code the column index is stored on the zero page and the restored from the zero page, 4 bytes and 6 cycles total. Since y is copied to the accumulator for the flip it would only require 3 bytes to push, pop and transfer! or pha / pla / tay

So this is what the character mirroring would look like:
lda.z vert,x
sta (zp_dst),y
tya ; C clear from asl
pha ; 3 cycles
eor #$1f
adc #8 ; leaves C clear!
tay
lda.z horiz,x
sta (zp_src),y
tax
lda.z vert,x
sta (zp_dst),y
pla ; 4 cycles
tay ; 2 cyclesOriginally there were 6 cycles which is now 9 cycles. Adding 3 cycles per mirrored character would be an average cost of around 254 cycles. This is clearly greater than the hoped for 60 cycles so saving this byte would cost a lot more cyclebytes than it saves!
Illegal instructions
Let’s get criminal for a minute.
This is what the start of the mirroring loop seems to have stabilized to at this point:
ldy #19
{
lda (zp_src),y
{
cmp #$40
bcc %
taxHere’s something interesting! lda and tax can be combined using an illegal 6502 instruction, lax! This would save 1 byte and 2 cycles for each character that needs to be mirrored.
ldy #19
{ ; 5+ + space: 5 other: 54
lax (zp_src),y
{
cmp #$40
bcc %
But wait! since both the accumulator and x contain the character we can shift the accumulator left (asl) and check the negative flag instead of cmp #$40 and save another byte! (the characters that can be mirrored are all in the range from $40 – $7d so the bit for $40 is set for all valid characters)
ldy #19
{ ; 5+ + space: 5 other: 54
lax (zp_src),y
{
asl
bpl %
That’s the inner loop (iterating over columns for each row) so any opportunities for the outer loop (iterating over rows)?

Currently the iterating over rows looks like:
- Set row pages countdown (2) and screen pointers
- for each row:
- add 40 to bottom row pointer
- iterate each column
- subtract 40 from top row pointer low byte
- if carry set (not crossing page) go back to loop start
- decrement top row pointer high byte
- decrement row pages counter
- if not zero go back to loop start
One observation here is that when the top row reaches page 3 ($300-$3ff) the loop should stop, so when decrementing the row pointer high byte becomes 3 the loop should stop, so something like this would eliminate the need for the top row countdown:
sec
lda $f7
sbc #40
sta $f7
bcs !
}
lda #3
dec $f8
cmp $f8
bne !
}
And there is an illegal instruction that combines dec and cmp! so here’s the entire outer loop including pointer setup using dcp:
lda #<$400+11*40
sta $f7
sta $f9
lda #>$400+11*40
sta $f8
sta $fa
{
sec
{
lda $f9
adc #40
sta $f9
{
bcc %
inc $fa
}
}
ldy #19
{
...
}
sec
lda $f7
sbc #40
sta $f7
bcs !
lda #3
dcp $f8
bne !
}
Order of mirrors
Let’s take a look at the order of mirroring, to recap: mirror horizontally, mirror the result vertically and then mirror the result of that horizontally again. After mirroring the value in the accumulator needs to be transferred to x so it can be used to index into the mirroring tables. Here’s the code for that:
tya ; C set from bcc
sta zp_tmp
eor #$ff
adc #39
tay
lda.z horiz,x
sta (zp_src),y
tax
lda.z vert,x
sta (zp_dst),y
tax
lda.z horiz,x
ldy zp_tmp
sta (zp_dst),y
But the original character can be mirrored horizontally and vertically eliminating the need for the last tax by just rearranging the order to vertical, then horizontal, then both!
asl ; character values $40 - $7d are flipped
bpl % ; characters<$40 are ignored (spaces)
lda.z vert,x
sta (zp_dst),y
sty zp_tmp
tya ; C clear from asl
eor #$ff
adc #40
tay
lda.z horiz,x
sta (zp_src),y
tax
lda.z vert,x
sta (zp_dst),y
ldy zp_tmp
2 cycles for each mirrorable symbol is a big deal! And a bonus byte saving!
Getting closer
With all the above optimizations so far I’m at about a cycle count of 4576 cycles plus 45 cycles per mirrored character. This puts the average just a bit above 1.15 MCB and it would be great to cross that limit, but I feel like there are no opportunities left. Just a couple of bytes or a few tens of cycles would help.
But there is nothing left. I’m pretty sure.

This is when I realize I can move the clc out of the bottom row adc block at the top as mentioned above in the row order section so that puts me at roughly just 3400 cyclebytes above 1.15 MCB.
So that must be the last thing I’ll ever find. But let’s keep looking at the code.
Maybe I can figure out a way to know the carry flag state so I can skip a clc or sec? Let’s spend a few days just staring at the code….
{
sec
{
{
lda $f9
adc #40-1
sta $f9
{
bcc %
inc $fa
}
}
ldy #19
{
lax ($f7),y
{
asl
bpl % ; characters<$40 are ignored (spaces)
lda.z vert,x
sta ($f9),y
tya ; Carry clear from asl
sta $f5
eor #$ff
adc #40 ; leaves C set
tay
lda.z horiz,x
sta ($f7),y
tax
lda.z vert,x
sta ($f9),y
ldy $f5
}
dey
bpl !
}
sec
lda zp_src
sbc #40
sta zp_src
bcs !
}
lda #3
dcp zp_src+1
bne !
}So the inner loop iterating over columns will end with the carry flag clear if the last character was a space, but set if the last character was mirrored because of the column flip. So that’s not something I can control.
But wait, maybe there is a way to rewrite the column math so the carry flag is clear?
Turns out initially when running code in zero page that’s what I was already doing by using eor #$1f and using an offset of 8. So if I just use those constants instead of $ff and 40 the result won’t overflow the adc! The carry flag is guaranteed to be clear after the loop.
Removing the sec which is called 12 times saves 24 cycles AND 1 byte!
Now I’ve finally reached my long sought goal of an MCB value less than 1.15!
137 bytes, 4532 + chars * 45 cycles, calculated with the average of 84.5 chars: 1141826.5
Finally I can retire and live off the profits of this huge breakthrough, thank you all for the support so far!
Oh wait, I can totally abuse the presentation!
Abusing the presentation
So we’ve been told that the presentation of the challenge entries will be running three screens with a pre-arranged random seed so everyone gets the same set of conditions for a fair comparison. The challenge code will be ran three times without resetting so it will be redundant to do any setup code after the first run.
The code that sets up the horizontal and vertical screen code mirroring tables is about 600 cycles and doesn’t need to be built for the second and third run.
But how to cheaply detect that the tables have been set up already? I’m overwriting only the necessary bytes in zero page so I need to find something that is a different value, and to avoid a compare it would be great if it was a byte with the high bit set or a zero so I can use bpl or bne to skip the mirror table setup.

I am setting $91 to $51 which turns out is the stop key indicator, which is $ff if the stop key is released and $7f when pressed. Seems unlikely to be pressed when running?
Here’s the setup code with the new experiment:
lda $91
bpl already_initialized
ldy #num_codes-1
{
ldx orig_codes,y
lda mirror_h_codes,y
sta.z horiz,x
lda mirror_v_codes,y
sta.z vert,x
dey
bpl !
}
already_initialized:This adds 4 whole bytes, but saves nearly 600 cycles after the first run!
Current status: 141 bytes; first run of 4537 + chars * 45 cycles so an average of 1175870 MCB which is a bit higher than 1.15 MCB but the following runs are 3937 + chars * 45 so an average of 1091270 MCB.
Running the initial pass and two passes without the setup gets the average to 1119470, or just below 1.12 MCB!
The result
As promised, here is the final code without the unique Carl-Henrik syntax!
cpu 6502ill
orig_codes = $a13
num_codes = 24
horiz = $0 ; will write to $40 - $7e
vert = $40 ; will write to $80 - $be
zp_src = $fc
zp_dst = $fe
zp_tmp = $fb
org $c000
lda $91 ; STOP key indicator, $ff if up, $7f if down
bpl already_initialized
ldy #num_codes-1
mirror_table_loop:
ldx orig_codes,y
lda mirror_h_codes,y
sta.z horiz,x
lda mirror_v_codes,y
sta.z vert,x
dey
bpl mirror_table_loop
already_initialized:
lda #<$400+11*40
sta zp_src
sta zp_dst
lda #>$400+11*40
sta zp_src+1
sta zp_dst+1
screen_page_loop:
sec ; carry unknown or clear when page loops
screen_row_loop:
lda zp_dst
adc #40-1 ; carry always set here
sta zp_dst
bcc bottom_row_same_page
inc zp_dst+1
bottom_row_same_page:
ldy #19
screen_column_loop:
lax (zp_src),y
asl ; character values $40 - $7d are flipped
bpl character_is_space ; characters < $40 are ignored (spaces)
lda.z vert,x
sta (zp_dst),y
tya ; C clear from asl
sta zp_tmp
eor #$1f
adc #8 ; leaves C clear!
tay
lda.z horiz,x
sta (zp_src),y
tax
lda.z vert,x
sta (zp_dst),y
ldy zp_tmp
character_is_space:
dey
bpl screen_column_loop
lda zp_src
sbc #40-1 ; C always clear from above
sta zp_src
bcs screen_row_loop
lda #3
dcp zp_src+1
bne screen_page_loop
rts
mirror_h_codes:
dc.b $49,$55,$4b,$4a ;Curves
dc.b $50,$4f,$7a,$4c ;Full corners
dc.b $6e,$70,$7d,$6d ;Half corners
dc.b $73,$6b,$71,$72 ;T junctions
dc.b $40,$42 ;Middle lines
dc.b $5b,$56 ;Crosses
dc.b $4e,$4d ;Diagonals
dc.b $51,$5a ;Filled Circle + Diamond
mirror_v_codes:
dc.b $4a,$4b,$55,$49 ;Curves
dc.b $4c,$7a,$4f,$50 ;Full corners
dc.b $6d,$7d,$70,$6e ;Half corners
dc.b $6b,$73,$72,$71 ;T junctions
dc.b $40,$42 ;Middle lines
dc.b $5b,$56 ;Crosses
dc.b $4e,$4d ;Diagonals
dc.b $51,$5a ;Filled Circle + Diamond
A comparison with the winner’s code
So here’s what I’m learning in addition to my trial and error process! Let’s just post the code as submitted first so I have something to refer to as I go.
This code begins with a commented out description of what it does!
/*
March Kaleidoscope Challange
by
Zsolt Zsila (ZseZse)
Tables
------
* HMirrorLookUpTable
A Dictionary with the horizontally mirrored screen codes by original screen codes
HMirrorLookUpTable[ScreenCode] = HorizontallyMirroredScreenCode
* VMirrorLookUpTable
The same as HMirrorLookUpTable, but with vertically mirrored screen codes
* ColumnOrderTable
A dictionary with horizontally mirrored X coordinates of the screen
ColumnOrderTable[x] = 39 - x
Where is x between 0 and 39
Algorythm
---------
TopScreenAddress = 1024
BottomScreenAddress = 1024 + 23 * 40
ScreenCodeIndex = 24
if isFirstRun
for ScreenCodeIndex = 23 to 0
y = ScreenCodeIndex
x = ScreenCodes[y]
y = y / 2
a = MirrorMagic[y]
HMirrorLookUpTable[x] = ScreenCodes[ScreenCodeIndex ^ (a && 1)]
VMirrorLookUpTable[x] = ScreenCodes[ScreenCodeIndex ^ (a >> 1]
next
for x = 39 to 0
ColumnOrderTable[x] = y
y++
next
end if
do
y = 19
do
a = x = [TopScreenAddress + y]
if a != 32 then
[BottomScreenAddress + y] = VMirrorLookUpTable[x]
y = ColumnOrderTable[y];
[TopScreenAddress + y] = x = HMirrorLookUpTable[x]
[BottomScreenAddress + y] = VMirrorLookUpTable[x]
y = ColumnOrderTable[y]
end if
y = y - 1;
until y == -1
BottomScreenAddress -= 40
TopScreenAddress += 40
until TopScreenAddressLo == #e0
*/
//#define ValidateEnabled
#if ValidateEnabled
#import "Validator.asm"
#endif
.cpu _6502
.pc = $c000 "Mirror, mirror"
.const TopScreenAddress = $20 //Address of 0th line, 0th column ($0400)
.const TopScreenAddressHi = $21
.const BottomScreenAddress = $22 //Address of 23th line, 0th column ($0798)
.const BottomScreenAddressHi = $23
.const ScreenCodeIndex = $24 //$18, only needed for first run
.const HMirrorLookupTable = $60 //Horizontally mirrored screen code pairs from $a0 ($60 + $40) to $cf
.const VMirrorLookupTable = $20 //Vertically mirrored screen code pairs from $60 ($20 + $40) to $8f
.const ColumnOrderTable = $2d //Column order table
.const ScreenCodes = $0a13 //Screen codes from MarchCompo.asm
ldx #04
CopyDefaultValues:
ldy DefaultValues,x //Copy default values to zero page
sty TopScreenAddress,x //TopScreenAddress, BottomScreenAddress
dex
bpl CopyDefaultValues
//The last copied default value is 0, so YR is 0 here, the ColumnOrderTable + 39 address's
//Value by default is $4c, a JMP code
cpy ColumnOrderTable + 39 //So if column order table already generated (ColumnOrderTable[39] == 0)
beq NextRow //We can skip the next part
//4 bytes for cca -1000 cycles from the 2nd run
ldx #39 //Build the column order table
NextColumnOrder: sty ColumnOrderTable,x //Store the value (Y is still zero here at first run)
iny
dex //Decrement position
bpl NextColumnOrder //Go to next one
GenerateMirrorLookupTables: ldy ScreenCodeIndex //Generate mirror lookup tables
ldx ScreenCodes,y //Get the current screen code from MarchCompo.asm
tya //Y = Y / 2, because in a full magic table every 2nd value is the same
lsr //So we gain 12 bytes in a 24 bytes length table and lose 3 bytes for this piece of code
tay
lda MirrorMagic,y //Get magic byte
lsr //Bits 2 & 1 are used to alter index for the vertical mirrored Screen Code
eor ScreenCodeIndex //VerticalScreenCode = ScreenCodes[y ^ a]
tay
lda ScreenCodes,y
sta VMirrorLookupTable,x //Store vertical screen code
lda #0 //Magic byte's 0.bit currently in carry flag
rol //Get it back
eor ScreenCodeIndex //VerticalScreenCode = ScreenCodes[y ^ a]
tay
lda ScreenCodes,y
sta HMirrorLookupTable,x //Store vertical screen code
dec ScreenCodeIndex
bpl GenerateMirrorLookupTables //Go to next one
NextRow:
ldy #19 //20 Columns (0..19) to process
NextColumn:
lax (TopScreenAddress),y //Get the screen code from the top left quarter
asl //If it is space
bpl Space //Then nothing to do here
lda VMirrorLookupTable,x //Get the vertically mirrored screen code from the look up table
sta (BottomScreenAddress),y //And write it to the bottom-left quarter of the screen
lda ColumnOrderTable,y //Set Y to next column (column = 39 - column)
tay
lda HMirrorLookupTable,x //Get the horizontally mirrored screen code from the look up table
sta (TopScreenAddress),y //And write it to the top-right quarter of the screen
tax //Get the already horizontaly mirrored screen code's
lda VMirrorLookupTable,x //Vertically mirrored pair code from the look up table
sta (BottomScreenAddress),y //And write it to the bottom right quarter of the screen
lda ColumnOrderTable,y //Set Y to next column (column = 39 - column)
tay
Space: dey
bpl NextColumn //Go to next one
SetBottomPreviousRow:
lda BottomScreenAddress //BottomScreenAddess -= 40 (previous row)
sbc #39 //Carry is clear here (asl)
sta BottomScreenAddress //Set new low byte
bcs SetTopNextRow
dcp BottomScreenAddressHi //Adjust high byteif needed & set carry
SetTopNextRow:
lda TopScreenAddress //TopScreenAddress += 40 (next row)
adc #39 //Carry is already set
sta TopScreenAddress //Set new low byte
bcc CheckNextRow
inc TopScreenAddressHi //Adjust high byte if needed
CheckNextRow: cmp #$e0 //If low byte of the top screen address is not equal to low byte of the 12th line
bne NextRow //Go to next row
#if ValidateEnabled
jsr Validate
#endif
rts //Otherwise let Shallan to count those cycles
MirrorMagic: .byte $05, $05, $05, $05, $05, $05 //The last byte is coming from DefaultValues, beacuse it is a zero :) -1 byte
.byte $01, $02, $00, $00, $03
DefaultValues: .byte $00, $04, $98, $07, $17 //TopScreenAddress = $0400, BottomScreenAddress = $0798
So the key to the better score is that the code is 12 bytes shorter than my version, the cycle speed is comparable. Maybe except for the first run in the winning code that is over 1000 cycles more. This code only runs one of the three iterations which means it is not a bad place to put code that is a little slower.
The piece of code that contain the saving is the mirroring table lookup generation, interestingly using something called “MirrorMagic”! Let’s take a look at how it is laid out.
- The mirroring is done in pairs, so each byte is used twice for each table. This is possible because of the order the original code stores the symbol screen codes.
- Only the lower 3 bits are used. Bit 0 is used for horizontal mirroring and bit 1 and 2 are used for vertical mirroring.
- Zero page address $24 contains $18 at startup and is called ScreenCodeIndex
- Loop start here..
- Read out y = value in ScreenCodeIndex (address $24, value starts at $18)
- Read out x = value ScreenCodes + y ($a13 table of valid screen codes in the base challenge code from Shallan)
- y is divided by 2 (lsr, because working in pairs)
- Accumulator is set to value in MirrorMagic + y
- Low bit is shifted out to Carry flag (horizontal offset)
- Accumulator is eor‘d with the value in ScreenCodeIndex. If the Accumulator was for example 2 that means that index 0 becomes 2 and index 2 becomes 0. For the vertical pairs some mirrored screen codes are two indices apart and some codes are 1 index apart.
- Transfer accumulator to y to read out the ScreenCodes value at that offset back into the accumulator. This is the vertically mirrored screen code!
- Now store the accumulator in the vertical mirroring table indexed by x
- Set the accumulator to zero, then rol the Carry Flag back into bit 0
- The same logic is done as for the vertical mirroring, but this time the horizontally mirrored screen code is generated and can be stored into that table
- ScreenCodeIndex is decremented and loop is repeated until the Negative Flag is set from the dec
So this code is kind of similar to my attempt at compressing the tables, except I was trying to run length encode the eor values instead which made the code more complicated. Maybe if I had thought of skipping the setup code in the 2nd and 3rd run I wouldn’t have given up on it, but I never thought to process the screen codes as pairs so that would have at best left my code size identical with compression as without and it would have been faster without!
The other thing that is different is the column position mirroring. I had also explored creating a mirroring table but concluded that sty tmp / tya / eor #$ff / adc #39 / tay / … / ldy tmp was cheaper. Let’s double check that..
So my version costs nothing upfront, but then costs 3+2+2+2+2+3 cycles = 14 cycles and 10 bytes (per mirrored character). For three runs the total would be 3549 cycles plus 10 bytes.
The winning version costs 40 * (3+2+2+3)-1 = 399 cycles and 8 bytes upfront and 10 cycles and 6 bytes per mirrored character. For three runs the total would be 2934 cycles plus 14 bytes.
I think paying four bytes for around 600 cycles is a good call! I should have stuck with the column position mirroring 🙂 Unfortunately I didn’t consider doing the setup only once when I went in that direction, so I would have budgeted 3732 cycles meaning higher cycles and bytes.
So the greater lesson would be to re-evaluate all your calculations when you decide to change how the code runs. Small losses can become large wins! But there are several steps I don’t think I would have thought to try in the winning code because I had already gone in a different direction.
One more thing..

In the middle of the challenge there was an argument about what zero page usage was allowed. This made me want to make an attempt at making a version without using zero page at all so I basically replaced all zero page instructions with absolute addressing. This means I need to maintain four pointers instead of two, and since the code relies on self modification the pointers need to be restored on the second run.
To detect if the setup code has already ran I’m checking if the first horizontal mirroring byte has been set since there is no known value in the allowed memory range at startup.
Apart from that the code is fairly similar so pretty much the same optimizations as the zero page version.
The code is 183 bytes, on the first run the cycle count is 4507 + chars * 42, or an average of 1474248 cyclebytes. For the following runs the cycle count is 3949 + chars * 42 or an average of 1372134 cyclebytes.
For three runs that should put the average at 1.4 MCB
cpu 6502ill
orig_chars = $a13
chars_count = 24
mirror_horizontal = $c800
mirror_vertical = $c900
org $c000
lda mirror_horizontal + $55
cmp #$49
beq restore_pointers
ldy #chars_count-1
setup_mirror_tables_loop:
ldx orig_chars,y
lda code_mirror_horizontal,y
sta mirror_horizontal,x
lda code_mirror_vertical,y
sta mirror_vertical,x
dey
bpl setup_mirror_tables_loop
bmi pointers_ok
restore_pointers
ldx #3
restore_pointers_loop:
ldy selfmod_ptrs,x
lda #>$400+11*40
sta src-$60+1,y
lda #<$400+11*40
sta src-$60,y
dex
bpl restore_pointers_loop
pointers_ok:
screen_row_page_loop:
sec
screen_row_loop:
lda dst2
adc #40-1
sta dst2
sta dst3
bcc dest_page_ok
inc dst2+1
inc dst3+1
dest_page_ok
ldy #19
column_loop:
src = *+1
lax $400+11*40,y
asl ; character values $40 - $7d are flipped
bpl not_mirror_character ; characters<$40 are ignored (spaces)
lda mirror_vertical,x
dst3 = *+1
sta $400+11*40,y
sty restore_y
tya ; C clear from asl
eor #$1f
adc #8 ; C still clear
tay
lda mirror_horizontal,x
dst1 = *+1
sta $400+11*40,y
tax
lda mirror_vertical,x
dst2 = *+1
sta $400+11*40,y
restore_y = *+1
ldy #0
not_mirror_character:
dey
bpl column_loop
lda src
sbc #40-1
sta src
sta dst1
bcs screen_row_loop
lda #3
dec src+1
dcp dst1+1
bne screen_row_page_loop
// fallthrough to rts
selfmod_ptrs:
dc.b src-src+$60, dst1-src+$60, dst2-src+$60, dst3-src+$60
code_mirror_horizontal:
dc.b $49,$55,$4b,$4a ;Curves
dc.b $50,$4f,$7a,$4c ;Full corners
dc.b $6e,$70,$7d,$6d ;Half corners
dc.b $73,$6b,$71,$72 ;T junctions
dc.b $40,$42 ;Middle lines
dc.b $5b,$56 ;Crosses
dc.b $4e,$4d ;Diagonals
dc.b $51,$5a ;Filled Circle + Diamond
code_mirror_vertical:
dc.b $4a,$4b,$55,$49 ;Curves
dc.b $4c,$7a,$4f,$50 ;Full corners
dc.b $6d,$7d,$70,$6e ;Half corners
dc.b $6b,$73,$72,$71 ;T junctions
dc.b $40,$42 ;Middle lines
dc.b $5b,$56 ;Crosses
dc.b $4e,$4d ;Diagonals
dc.b $51,$5a ;Filled Circle + Diamond
One thought on “Shallan Discord March Coding Challenge!”