Updates: Various improvements have been made since the competition ended and has been included towards the end of the post. My best post challenge is 42 bytes and Gair Straume has provided a 39 byte solution based on the findings of other solutions!
September meant another challenge, and I’d missed out on the July optimization challenge because I was busy finishing up Lost in Random at Thunderful. But this month was a little different, just a screenshot and the following rules:
SEPTEMBER OPTIMIZATION CHALLENGE
1. The aim is to write the smallest program that generates the image provided.
2. There is a mathematical pattern to the image, working this out could make the task much easier. However any method to obtain the same pattern is valid.
3. This is a prg size challenge only, speed does not matter. Smallest PRG size wins
4. You can use any trick you want to produce the image in the smallest size possible as long as it runs in VICE.
5. Programs will be dropped into the latest version of VICE using default installation settings with the exception that Autostart will be set to Inject to RAM.
6. The provided PRG is to demonstrate the final values in memory to help those who may be colorblind, it is very inefficient and does not represent any useful algorithm.
7. Submissions must be made in the form of a prg and the closing date for entries is 9:30pm GMT on the 25th September 2021, and winners will be announced on that nights stream.
Here is the screenshot

So what is going on here?
The character is filled circle, screencode 81. There is one circle, one space, two circles, three spaces, five circles, eight spaces etc. This is a Fibbonacci series, basically adding the two previous values for each following value or:
1, 0+1, 1+1. 1+2, 2+3, 3+5, 5+8…
And then it is just a matter of picking colors. The color value for each section is the same as its count so that makes it a little easier.
My intuition is that you can use KERNAL functions to print characters and scroll the screen, but I am not that familiar with those so I’ll focus on just screen clear and print directly with code. So first let’s try that!
Startup choice
There are a few choices, regular basic startup would cost at least 10 bytes so that’s maybe the easiest to get started but almost a waste of time, the smallest choice is probably putting the code around $73 but the smallest code clear the screen with spaces is a jsr so starting by loading over the stack return address could do that saving a byte, so let’s give it a go!
First Attempt
cpu 6502ill
const zpScr = $6c
const zpCol = $f3
const zpA = $a8
const zpB = $a9
const zpY = $aa
org $1f8
dc.w $e544-1 // same as jsr screen clear
dc.w *+1 // then return to start address
ldy #0
; sty zpScr // this is already 0 after reset
; sty zpCol // this is already 0 after reset
; lda #4
; sta zpScr+1 // this is already $400 after screen clear
; lda #$d8
; sta zpCol+1 // this is already $d8 after screen clear
{
jsr StepColor // iterate fibonacci value
tax
{
lda #$51 // Draw filled circles
sta (zpScr),y
lda zpA
sta (zpCol),y
{
iny
bne %
jsr DoWrap
}
dex
bne !
}
jsr StepColor
// iterate fibonacci value
jsr CheckWrap // skip N spaces
tya
adc zpA
tay
jsr CheckWrap
bcc ! // loop
}
CheckWrap:
bcc NoWrap
DoWrap:
inc zpScr+1
inc zpCol+1
bpl * // hang here forever to stop filling more memory
clc
NoWrap:
rts
StepColor:
lax zpA
; lda zpA ; initial a
; tax
;clc
adc zpB ; c = a+b
stx zpB ; b = a
sta zpA
rts
63 byte file from this code, not too painful, but probably easy to improve.
Iterating on the same idea a bit
cpu 6502ill
const zpScr = $6c
const zpCol = $f3
const zpA = $a8
const zpB = $a9
const zpY = $aa
org $1f8
dc.w $e544-1
dc.w *+1
ldy #0 ; y = 0, x = 1
{
tya ; a = y = zpA
adc zpB ; c = a+b
sty zpB ; b = a
tay ; y = a = zpA already
{
dex
bne %
{
dey
php
pha
sta (zpCol),y
lda #$51
sta (zpScr),y
pla
plp
bne !
}
ldx #2
tay
}
jsr CheckWrap
adc zpScr
sta zpScr
sta zpCol
jsr CheckWrap
bcc !
}
CheckWrap:
bcc NoWrap
clc
inc zpScr+1
inc zpCol+1
bpl *
NoWrap:
rts57 bytes file size! This is going down fairly fast.
New strategy
So rather than having a loop to draw circles and then skipping N characters maybe the two steps could be combined? Maybe instead of clearing the screen the code could write spaces each second iteration.
To alternate between two values the easiest operation is EOR, to switch from 81 (filled circle) to 32 (space) just EOR the value with #(81 EOR 32) and we can use the same loop for both the circle and the space sections!
First version with new strategy
cpu 6502ill
const zpCountLo = $2b
const zpCountHi = $2a
const zpBLo = $29
const zpBHi = $28
org $41
{
{
zpChar = *+1
lda #$51
zpScrPage = *+2
sta $400-$ff,x
zpA = *+1
lda #1
zpColPage = *+2
sta $d800-$ff,x
inx
{
bne %
inc zpScrPage
inc zpColPage
bpl * // hang here when about to write over zero page
}
dec zpCountLo
bne !
dec zpCountHi
bpl !
; acc = zpA
tay
adc zpBLo
sty zpBLo
sta zpA
sta zpCountLo
lda zpBHi
adc #0
sta zpBHi
sta zpCountHi
lda zpChar
eor #$51^$20
sta zpChar
bne !
}
}So this gives a filesize of 54 bytes, pretty good but still larger than my January challenge entry. Would be kind of fun to go a little smaller with this one!
Another iteration
Time for breaking the math a little bit. On screen there is only one segment that is greater than 255 characters so only the first length needs to be correct and the next round doesn’t matter if it is way too long. So instead of incrementing the high byte with lda / adc #0 / sta I’ll just ROL it!
cpu 6502ill
const zpCountLo = $2b
const zpCountHi = $2a
const zpBLo = $29
const zpBHi = $28
org $43
{
{
zpChar = *+1
lda #$51
zpScrPage = *+2
sta $400-$ff,x
zpA = *+1
lda #1
zpColPage = *+2
sta $d800-$ff,x
inx
{
bne %
inc zpScrPage
inc zpColPage
bpl *
}
dec zpCountLo
bne !
dec zpCountHi
bpl !
; acc = zpA
tay
adc zpBLo
sty zpBLo
sta zpA
sta zpCountLo
rol zpBHi // sneaky replacement for adc #0
lda zpBHi
sta zpCountHi
lda zpChar
eor #$51^$20
sta zpChar
bne !
}
}52 bytes file size! But now the race below 50 bytes begin, time to mess things up and see what falls out!
Next version
cpu 6502ill
const zpCountLo = $2b
const zpCountHi = $2a
const zpBLo = $29
const zpBHi = $28
org $45
{
tay
{
zpChar = *+1
lda #$51
zpScrPage = *+2
sta $400-$ff,x
zpA = *+1
lda #1
zpColPage = *+2
sta $d800-$ff,x
inx
{
bne %
inc zpScrPage
inc zpColPage
bpl *
}
dec zpCountLo
bne !
dey
bpl !
; acc = zpA
tay
adc zpBLo
sty zpBLo
sta zpA
sta zpCountLo
lda zpChar
eor #$51^$20
sta zpChar
rol zpBHi
lda zpBHi
}
bcc !
}
50 bytes file size so far, would be great to get one byte lower!
More code..
Looking over the previous version it is pretty silly to lda then tay so easy fix!
cpu 6502ill
const zpCountLo = $2b
const zpBLo = $29
const zpBHi = $28
org $48
{
{
inx
{
bne %
inc zpScrPage
inc zpColPage
bpl *
}
zpChar = *+1
lda #$51
zpScrPage = *+2
sta $400-$100,x
zpA = *+1
lda #1
zpColPage = *+2
sta $d800-$100,x
dec zpCountLo
bne !
dey
bpl !
tay ; a = zpA
adc zpBLo
sty zpBLo
sta zpA
sta zpCountLo
lda zpChar
eor #$51^$20
sta zpChar
rol zpBHi
ldy zpBHi
}
bcc !
}51 bytes file size! Decent but time to get a little obsessive.
Next!
cpu 6502ill
const zpCountLo = $2b
const zpA = $ac
const zpBLo = $fe
const zpBHi = $18
const zpChar = $ce
org $47
{
ldy.z zpBHi
lda.z zpChar
eor #$51^$20
sta.z zpChar
{
lda zpChar
inx
{
bne %
inc.z zpColourPage
beq *
inc.z zpScreenPage
}
zpScreenPage = *+2
sta $400-$100,x
lda zpA
zpColourPage = *+2
sta $d800-$100,x
dec.z zpCountLo
bne !
dey
bpl !
}
tay ; a = zpA
adc.z zpBLo
sty.z zpBLo
sta.z zpA
sta.z zpCountLo
rol.z zpBHi
bcc !
}49 bytes! Let’s leave it here and move on… Or wait, this is me, I can’t stop.
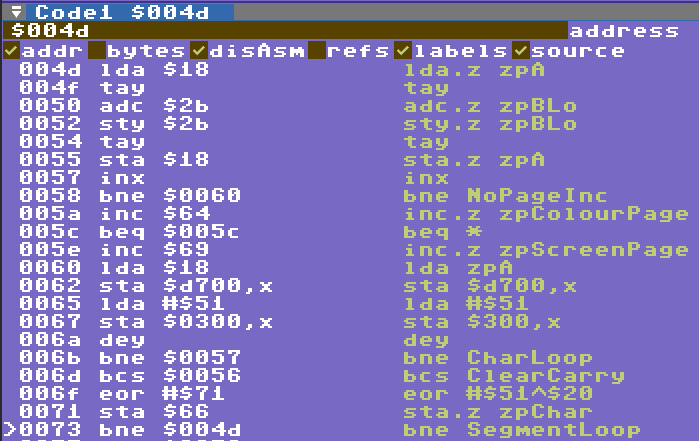
Final version!
cpu 6502ill
const zpCountLo = $2b
const zpBLo = $fe
const zpBHi = $a8 // also tay
org $48
SegmentLoop:
ldx.z zpBHi
CharLoop:
iny
bne NoPageInc
inc.z zpColourPage
beq *
inc.z zpScreenPage
NoPageInc:
zpA = *+1
lda #1
zpColourPage = *+2
sta $d800-$f3,y
zpChar = *+1
lda #$51
zpScreenPage = *+2
sta $400-$f3,y
dec.z zpCountLo
bne CharLoop
dex
bpl CharLoop
eor #$51^$20
sta.z zpChar
lax.z zpA
adc.z zpBLo
sta.z zpCountLo
stx.z zpBLo
sta.z zpA
rla.z zpBHi // <- start at one byte plus this instruction so 'tya'
bcc SegmentLoopSo the final results has the winner at 44 bytes. I don’t have that code but I expect it is using KERNAL functions to save bytes. Both GeirS and ZseZse reached that score!
Here are the final scores, these includes BASIC solutions that ended up a little bit larger:

Post competition update
It is perhaps easy to see better solutions after the deadline and just looking at the post competition analysis on the stream, but I had this thought that the carry flag may not need to be rol’d/adc’d into another register or memory byte but because I was using bcc to loop the code I needed to make sure it was clear. Turns out bne would have allowed me to do that and just remove all the capture and outer loop decrement.
This version also swaps the usage of x and y because the start values are better (x=$ff and y=$01), there might be another byte to save here, we’ll see!
cpu 6502ill
const zpCountLo = $2b
const zpBLo = $fe
const zpBHi = $a8
org $4c
ClearCarry:
clc
SegmentLoop:
CharLoop:
inx
bne NoPageInc
inc.z zpColourPage
beq *
inc.z zpScreenPage
NoPageInc:
zpA = *+1
lda #1
zpColourPage = *+2
sta $d700,x
zpChar = *+1
lda #$51
zpScreenPage = *+2
sta $300,x
dey
bne CharLoop
bcs ClearCarry
eor #$51^$20
sta.z zpChar
lda.z zpA
tay
adc.z zpBLo
sty.z zpBLo
tay
sta.z zpA
bne SegmentLoop
43 bytes file size! I could have won if I had got so stuck on bcc.. Now I’m ready to dig in to the other entries!
Can you really leave anything close to 42 bytes? No, have to reach 42 bytes by hiding a clc inside a sta zp:
const zpBLo = $2b ; = 1
const zpA = $18 ; = 0, clc
org $4d
SegmentLoop:
lda.z zpA
tay
adc.z zpBLo
sty.z zpBLo
tay
ClearCarry = *+1 // this is a hidden clc instruction
sta.z zpA
CharLoop:
inx
bne NoPageInc
inc.z zpColourPage
beq *
inc.z zpScreenPage
NoPageInc:
lda zpA
zpColourPage = *+2
sta $d700,x
zpChar = *+1
lda #$51
zpScreenPage = *+2
sta $300,x
dey
bne CharLoop
bcs ClearCarry
eor #$51^$20
sta.z zpChar
bne SegmentLoop
Geir Straume solution
Code, tabs replaced with spaces for interweb readability. The explanation is in the comments
.var NextNumLo = $35 // Lo byte of next number (initially 0)
.var NextNumHi = $36 // Hi byte of next number (initially 0)
NumberLoop:
sty NextNumLo // Set lo byte of next number (required for the first iteration only)
ldx NextNumHi // Get hi byte of next number
lda PrevNumLo:#0 // Get lo byte of previous number
jsr $b69a // Adjust number for next iteration using some code in BASIC ROM (see https://www.pagetable.com/c64ref/c64disasm/#B69A)
sty PrevNumLo // Set lo byte of previous number for use in next iteration
sty $0286 // Set char color used by KERNAL (see https://www.pagetable.com/c64ref/c64mem/#0286)
lda CurrChar:#$d1// Get current PETSCII char value ($d1 is a solid circle)
CharLoop:
bit $07e6 // Check screen address to the left of the bottom rightmost char
bvc PrintChar // Branch if there's still a space there (bit 6 is clear)
sta $d5 // Change line length to prevent further scrolling (see https://www.pagetable.com/c64ref/c64mem/#00D5)
dec CharLoop // Change opcode 'bit' to 'anc #' (see Note 1 below)
PrintChar:
jsr $f1ca // Print char on screen using a KERNAL routine (see https://www.pagetable.com/c64ref/c64disasm/#F1CA)
dey
bne CharLoop // Loop for lo byte
dex
bpl PrintChar // Loop for hi byte
eor #$f1 // Toggle char value between $d1 (solid circle) and $20 (space)
sta CurrChar
ldy NextNumLo // Get lo byte of next number
bcc NumberLoop // Branch always (This is the entry point at location $0073. Initially, y will be 1 here.)
The magic referenced for Note 1 is
NOTES:
1. The opcode change will cause a non-ending loop, executing "dummy" instructions in a different code path than before:
$005b: anc #$e6
$005d: slo $50
$005f: nop $85
$0061: cmp $c6,x
$0063: sre $ca20,y
$0066: sbc ($88),y
$0068: bne $005b
See the PDF at https://csdb.dk/release/?id=198357 for detailed information about unintended 6510 opcodes.This is exactly what I was expecting from Geir given his solution to this: https://nurpax.github.io/posts/2019-08-18-dirty-tricks-6502-programmers-use.html
I think that understanding the basic and kernal code a little better would have helped me here and Geir shows exactly how to achieve it!
Geir also created the first post competion improvement at 43 bytes:
.var NextNumLo = $2b // Lo byte of next number (initially 1)
* = $004c // Code loads here so that the entry point for autostart will be at location $0073
NumberLoop:
lax NextNumLo // Get lo byte of next number
adc PrevNumLo:#0// Add lo byte of previous number
sta NextNumLo // Set new lo byte of next number
stx PrevNumLo // Set lo byte of previous number for use in next iteration
stx $0286 // Set char color used by KERNAL (see https://www.pagetable.com/c64ref/c64mem/#0286)
ldy NextNumHi:#0// Get hi byte of next number
rol NextNumHi // Adjust hi byte of next number
lda CurrChar:#$d1 // Get current PETSCII char value ($d1 is a solid circle)
CharLoop:
bit $07e6 // Check screen address to the left of the bottom rightmost char
bvc PrintChar // Branch if there's still a space there (bit 6 is clear)
sta $d5 // Change line length to prevent further scrolling (see https://www.pagetable.com/c64ref/c64mem/#00D5)
dec CharLoop // Change opcode 'bit' to 'anc #' (see Note 1 below)
PrintChar:
jsr $f1ca // Print char on screen using a KERNAL routine (see https://www.pagetable.com/c64ref/c64disasm/#F1CA)
dex
bne CharLoop // Loop for lo byte
dey
bpl PrintChar // Loop for hi byte
eor #$f1 // Toggle char value between $d1 (solid circle) and $20 (space)
sta CurrChar
bcc NumberLoop // Branch always (This is the entry point at location $0073)
After SCaslin’s 40 byte version without kernal calls Geir created this 40 byte version using kernal calls:
* = $0054
ClearCarry:
clc
CharLoop:
bit $07e6 // Check screen address to the left of the bottom rightmost char
bvc PrintChar // Branch if there's still a space there (bit 6 is clear)
sta $d5 // Change line length to prevent further scrolling
PrintChar:
php // Save carry and overflow flags
jsr $f1ca // Print char on screen using a KERNAL routine
plp // Restore flags
bvs * // Loop forever here if we're done
dey
bne CharLoop // Loop for lo byte
bcs ClearCarry // Branch if number > 255
eor #$f1 // Toggle char value between $d1 (solid circle) and $20 (space)
sta.z Char
lax (ColorAddr),y // Calculate
adc Num:#0
stx Num
tay
Entry:
sty ColorAddr:$0286 // On first entry: a=$f2, x=$ff, y=$01, carry clear
lda Char:#$d1
bne CharLoop // Branch always
And then a 39 byte version! This one avoids the clc by branching to ClearC which is the parameter to an stx, resulting in an rra $8ca8 that clears the carry and the next instruction is stx $02 which then returns to the CharLoop for another 256 characters.
* = $0055
CharLoop:
bit $07e6 // Check screen address to the left of the bottom rightmost char
bvc PrintChar // Branch if there's still a space there (bit 6 is clear)
sta $d5 // Change line length to prevent further scrolling
PrintChar:
php // Save carry and overflow flags
jsr $f1ca // Print char on screen using a KERNAL routine
plp // Restore flags
bvs * // Loop forever here if we're done
dey
bne CharLoop // Loop for lo byte
bcs ClearC // Branch if number > 255
eor #$f1 // Toggle char value between $d1 (solid circle) and $20 (space)
sta.z Char
lax (ColorAddr),y // Calculate
adc Num:#0
stx ClearC:Num // A branch to 'ClearC' executes 'rra $8ca8' which clears the carry
tay
Entry:
sty ColorAddr:$0286 // On first entry: a=$f2, x=$ff, y=$01, carry clear
lda Char:#$d1 // Get current PETSCII char value ($d1 is a solid circle)
bne CharLoop // Branch alwaysZseZse solution
This version uses a table for the fibonacci values instead of calculating them and the code comes with a lengthy explanation of how it works
Every 2nd (2m + 1) Fibonnacci number's low byte (stored backwards for some reasons)
We neither need to store the even indexed ones (F(2m)) nor the first one F(1)),
because:
- The F(1)=1 is in XR after the calling of the screen clearing routine at Entry
- Let's say n = 2m + 1. If we write F(n) dots to the screen to the address S(m)
the next F(n + 2) dots will be drawn at S(m) + F(n + 2).
So by definition S(0) = 1024 and for every S(m + 1) = S(m) + F(2m + 1 + 2):
M S(M) N F(N) F(N + 2)
0 1024 1 1 2
1 1026 3 2 5
2 1031 5 5 13
3 1044 7 13 34
...and so on.
From this values we can know
* where to draw dots (S(M)),
* how many dots we have to draw (F(N))
* where we will start to draw the next dots (S(M) + F(N + 2))
//
|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|...
|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|...
|2|2|2|2|2|2|3|3|3|3|3|3|3|3|3|3|4|4|4|4|4|4|4|...
|4|5|6|7|8|9|0|1|2|3|4|5|6|7|8|9|0|1|2|3|4|5|6|...
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+...
|O| |O|O| | | |O|O|O|O|O| | | | | | | | |O|O|O|...
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+...And this is the code (again edited for interweb readability with comments). Because of the DotLengths table the remaining code gets really small!
As in Geir’s code above, the explanation is in the comments
DotLengths: .byte 98, 233, 89, 34, 13, 5, 2
DotLoop:
lda #SCREEN_CODE_DOT //Get the screen code of the dot character
dec SCREEN_COLUMN //Decrement the column offset by one
jsr KERNAL_DRAW_CHAR //Draw a char with color XR to $d1/$d2 (Screen Pointer) and to $f3/$f4 (Color Pointer)
tya //After calling draw char, YR holds the value of $d3, by which I can check if it is already zero
bne DotLoop //Draw next dot with the same color if needed
lax.zp DotLengthPointer: DotLengths + 6 //Set AC and XR to the "next" Fibonacci number
ChuckNorrisLoop:
beq ChuckNorrisLoop //If AC = 0 we execute Chuck Norriss's favorite loop (at least twice, of course)
dec.zp DotLengthPointer //Decrement the Fibonacci number pointer
.byte BIT_ABSOLUTE //Hide the next instruction
IncrementHigh:
inc SCREEN_HIGH //Increment the high byte of the screen pointer
ror MAGIC_MASK //Rotate the magic mask to the right by one.
bcs IncrementHigh //Increment again the high byte if needed
//The magic mask by default is $a0: %10100000
//We store here the extra high byte adjusting markers. If there is a Carry after ROR we
//add extra 256 bytes to the start address
adc SCREEN //Increase the screen address's lower byte
sta SCREEN
.byte BIT_ZERO_PAGE //To hide the clear screen routine from the 2nd iteration (BIT $20 / NOOP $E5)
Entry:
jsr KERNAL_CLEAR_SCREEN //This is the entry point, we start with a screen clearing
stx SCREEN_COLUMN //Store the new offset
bvc DotLoop //Jump in all circumstancesPretty cool to see a very different approach with the same number of bytes as the other winner!
Jesper Gravgaard’s solution
Jesper reached 45 bytes which is one more than the winners but smaller than mine.
This has been edited with less spaces to fit on the interweb page, very detailed comments but mostly fits on the line intended!
.label f1 = $40 // Holds fib[n-1]. $40 is zero on the initial CHRGET call
.label bit9 = $41 // Holds 9th bit of fib[n]. $41 is zero on the initial CHRGET call
* = $4a // Start address for the program
main: // Calculate and renderthe next fibonnaci number
// Y holds cursor lo-byte. Y is $01 on the initial CHRGET call
// Carry is always clear here. after the loop below and on the initial CHRGET call
lax f1 // Immediate value holds fib[n-1]
adc f0: #1 // Calculate fib[n]=fib[n-2]+fib[n-1]. Immediate value holds fib[n-2].
stx f0 // Set fib[n-2] to fib[n-1] for the next round
rol bit9 // Capture the 9th bit in carry to render an extra 256 chars when needed.
sta f1 // Set fib[n-1] to fib[n] for the next round
tax // X is fib[n]
render:
lda f1 // Get fib[n]
sta colors: $d7ff,y // Store in color ram (initial x-value is $ff so this is increased at the start)
lda char: #$51 // Char-value to store on screen. Modified on for each round.
sta screen: $03ff,y // Store on screen (initial Y-value is $01)
iny // Increase cursor lo-byte
bne !+ // Do we need to increase cursor hi-byte?
inc.zp screen+1 // Increase screen cursor hi-byte
inc.zp colors+1 // Increase color cursor hi-byte.
// The render loop partially overwrites itself when the color cursor crosses $0000.
// The fib[n]-value at this point is $05 and the char-value is $20.
// This modifies the first 3 bytes of the render-loop to $05, $25, $25 -
// so the first 3 instructions become ORA $25 AND $FF ISC $2049,X
// These modifications are luckily benign and stop any further self-modification since
// STA colors,y is overwritten.
// Another piece of luck is that the color cursor hi-byte is not overwritten and can
// therefore be used to stop the algorithm.
exit:
beq exit // Are we all done? We are done when the color cursor hi-byte overflows to $00
!:
dex // Are we done rendering fib[n] chars?
bne render
ror bit9 // Is fib[n] 9th bit set? Also clears bit9.
bcs render // If the 9th bit is set we render 256 extra chars. X is already 0.
eor #($51^$20) // Flip the drawing char between space ($20) and filled circle ($51). A already holds the current char-value.
sta char
.assert "@CHRGET", *, $73 // Check that the PC is now at $73. $73 holds the CHRGET function, which is called when loading is complete.
bne main // Calculate the next fibonacci number in the sequence. Also the entry point of the program when CHRGET is called after the load. Z is clear on the initial CHRGET call.
Jesper’s solution feels close to my final entry, but using a zero page address to capture carry with rol and ror where I just used rol and used the value as an outside loop counter. This solution saves 3 bytes!
Following my post competition 42 byte version Jesper took the clc trick but swapped x and y to allow for lax to replace my lda/tay to reach a file size of 41 bytes:
.label f1 = $18 // Holds fib[n] ; $18 is initially zero. $18 is also the CLC opcode
* = $4e // Start address for the program
main:
lax.z f1 // Load fib[n-1] into X and A
adc.z f0: #1 // Calculate fib[n]=fib[n-2]+fib[n-1].
// Immediate value holds fib[n-2]. Carry holds bit 9.
stx.z f0 // Set fib[n-2] to fib[n-1] for the next round
tax // X is fib[n]
sta.z clear_carry: f1 // Set fib[n-1] to fib[n] for the next round.
// The operand is a hidden CLC instruction.
render:
lda.z f1 // Load fib[n].
sta colors: $d7ff,y // Store in color ram (initial Y-value is $01)
lda symbol: #$51 // Char-value to store on screen. Modified on for each round.
sta screen: $03ff,y // Store on screen (initial Y-value is $01)
iny // Increase cursor lo-byte
bne !+ // Do we need to increase cursor hi-byte?
inc.z screen+1 // Increase screen cursor hi-byte
inc.z colors+1 // Increase color cursor hi-byte. The render loop partially overwrites
// itself when the color cursor crosses $0000.
// These modifications are luckily benign.
beq * // Are we all done? We are done when the color cursor hi-byte
// overflows to $00
!:
dex // Are we done rendering fib[n] chars?
bne render
bcs clear_carry // If the 9th bit is set we render 256 extra chars. X is already 0.
eor #($51^$20) // Flip the drawing char between space ($20) and filled circle ($51).
// A already holds the current char-value.
sta.z symbol
bne main // Calculate the next fibonacci number in the sequence.
// Also the entry point of the program when CHRGET is called after
// the load. Z is clear on the initial CHRGET call.SCaslin’s approach
SCaslin landed at 45 bytes so also higher than the winner but lower than me, not quite as much info in the code but let’s check it out:
// Code challenge - Fibonacci
// SCaslin
*= $4a
start: inx // x=0
lp: txa
adc temp1:#1 // fibonacci calc
stx temp1
tax
tay // loop counter in y & carry
lda char:#$20 // char block to print
eor #$71 // toggle between block and space
sta char
col: stx $d800 // colour
scn: sta $0400 // screen
inc col+1 // inc colour/screen
inc scn+1
bne !+
inc col+2
inc scn+2
!: dey // loop count
bne col
bcc lp // loop counter top bit in carry
cpx #$b7 // when count>256 x will be $79 then $62, trap $62 as finished, also clear carry
done: bpl done
bcc col
Entry: bcc start // $73 entry point a = $f2 y = $01 x = $ff, carry clearSo this looks a little more like mine, but interestingly not using indexed writes for screen and color but incrementing both low and high bytes of the addresses. Code looks very readable too so I think it is easy to follow the code and comments to see what is going on! No basic/kernal calls and no illegals makes it even easier to read.
Of course, after I posted my 43 byte version there is an updated SCaslin post competition version too!
*= $53
charlpcc:
clc
charlp: bit $07e6
bvc !+
sta $d5
!: php
jsr $f1ca
plp
!: bvs !-
dey // loop count
bne charlp
bcs charlpcc // >256
lp: eor #$f1
sta $77
lax $0286
adc temp1:#0 // fibonacci calc
stx temp1
tay
Entry: sty $0286 // $73 entry point a = $f2 y = $01 x = $ff, carry clear
lda char:#$d1 // char block to print
bne charlp41 bytes! Pretty amazing. Looks like it is using some tricks from Geir Straume to reach this size.
SCaslin has since provided a 40 byte version:
*= $4f
start: sty $18
lp: tya
col: sta $d800-$ff,x
lda char:#$51
scn: sta $0400-$ff,x
inx
bne !++
inc scn+2
inc col+2
!: beq !-
!: dec $18
bne lp
bcs start+1
eor #$31
sta char
tya
adc fib:#0
sty fib
tay
Entry: bne start
39 bytes is the current post competition leader.

One thought on “September 2021 Optimization Challenge”